
The origins
In April 1999 two schoolboys, Thomas Wagner and Aaron Praktiknjo, wanted to put a homepage on the Internet, because it was just "in". It should be a site that benefits the general public. And because there was a cover version on the radio – which wasn't unusual in the 90s, because there were many cover versions in the charts at that time – the idea for the topic of the homepage was born: cover versions in the charts.Brainstorming and an additional screening of the current Top 100 resulted in around 50 cover versions, each of which was compared with the (presumed) original in tabular form with their artist and title. Everything else was done by Thomas Wagner. On April 14, 1999, he finally created a banner with the name of the site on a colorful background and uploaded everything to the web server of his Internet access provider. As the path http://www1.inetmail.de/w9000185/cover/ was difficult to remember, a short and easier to remember subdomain had to be found at a provider where you could redirect to the more complicated path for free. So the subdomain cover.here.de was created. Of course, this address was also registered at two dozen search engines.
The visitors of the website – which in the beginning was in German only were asked to report additions by e-mail. And it did not take long, until not only the site was found, but after some days also already the first people made submissions, which Thomas Wagner maintained in regular intervals.
Fast growth
From old backups we know today that on August 30, 1999, only four and a half months later, we already had 1,346 entries together. While on the first day everything had been on a single HTML page with olive-green background, this would not have made sense anymore, because the loading times would have been too long. (With the so-called 56k modem one actually reached about 40 kbit/s, similar to when today the mobile Internet was restricted). So the cover version list was divided into 5 lists, which interestingly were sorted by cover artists, not by songs. This was not a real database, but simply a listing in tables on HTML pages. That looked like this – with a newly created navigation frame:



There was no search function yet. One was completely dependent on the corresponding functionality of the web browser. With increasing growth and ongoing subdivision of the cover version list, it became more and more difficult to find the right list to search in.
Finally, on March 5, 2000, the sorting was changed to one by cover titles, and each initial letter (as well as the numbers 0-9 and the rest) got its own list. On this day a search function finally came up,which displayed all found entries from the list.
In the middle of April 2000 the 2000th cover version was already registered. It was the Jetzendorfer Hinterhof-Musikanten with "La Bamba", one of about 40 other versions of this song that were included in the list at that time. (By the way, it is not known why the entry was created later anew and is now in the database with the creation date March 7, 2004.)


Since the end of May 2001 Thomas Wagner was no longer alone with the maintenance of the website. Herbert Zach joined him and has remained a hard-working member of the editorial staff until today. Herbert had gotten to know the website on May 28, 1999 thanks to the presentation in the television show NBC GIGA and had since then regularly contributed to the dataset by e-mail.

The new domain coverinfo.de
On June 9, 2001, paid web space for the operation of the website was rented for the first time. In this context, the website cover.here.de should receive its own domain.The desired domain would have been cover.de, but it was given to a cover band called COVER. From the news headlines it was known that there would soon be a new top-level domain: .info, which would not start until June 26, 2001. Aware of this news, the wish came up to get the domain cover.info, but you couldn't order it on June 9th. For this reason, the combination coverinfo.de was chosen as domain. Two weeks later coverinfo.de joined the discussion forum of Coverversion.de.
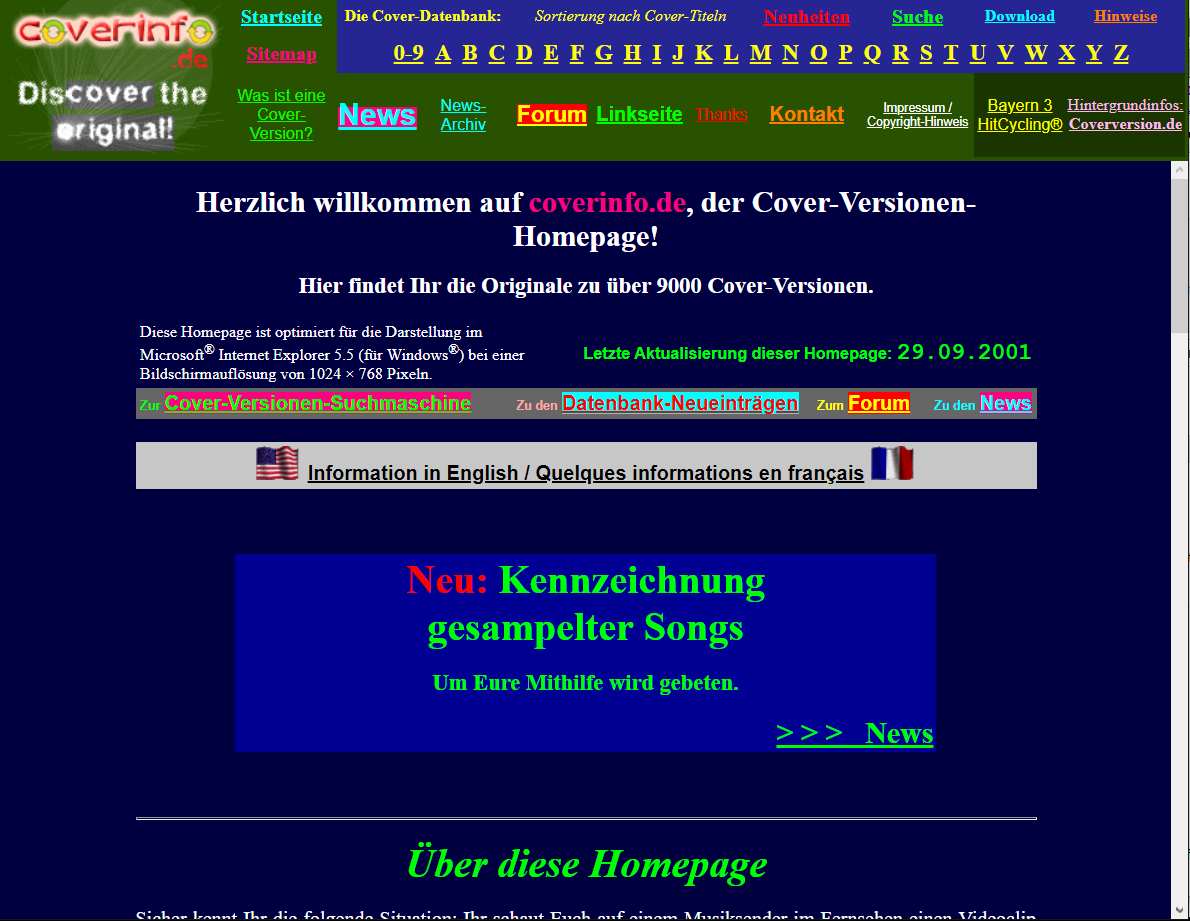


The site hasn't been called "Cover versions in the charts" since then, because we had long ago moved away from the initial list of songs that made it into the charts.
On September 29, 2001 we started to distinguish musical quotations (samples and replayed elements) from the cover versions in the list. Records which are full cover versions now had a "C" for cover and the others a "S" for sample in the right column (from April 28, 2003 instead a "Z" for the generic term "quote" [German: Zitat], which includes samples).
Overloaded technology
Since 2002 coverinfo.de was a little brighter and a little less colorful. In April 2002, 3 years after the launch of the website, we already had over 19,400 entries.At that time, the whole thing was still not a real database, but a search in HTML pages, which was far from performant, which eventually brought the server to its knees.




Finally a real database
On July 1, 2002, there was finally an end to collecting the data in a large Excel file and exporting it to HTML files for the web server at more or less regular intervals using virtual basic scripts. Our MySQL database was launched. This reduced the response time of the search function and since then, changes to the database go live immediately and not after several days.



Behind the scenes we worked with Microsoft Access 2000, which was connected to the MySQL database via an ODBC interface. All the technical solutions that had been in use since 2000 were developed for us by a few hard-working users of the website. We thank Achim Kaiser, Gerd Nachtsheim, Mike Wilhelm and Björn Hutzler. Without them coverinfo.de would never have come this far, which is why we thank them for their work.
It's getting more professional
On September 1, 2003, the website presented itself for the first time in a professional looking design, which was donated to us by a user of the site, Marcel C.





Holger Kung's work
But on October 4, 2007, the website was relaunched for the first time completely by the editorial staff itself, more precisely by its member Holger Kung. The essential design elements of the site designed by Marcel C. were preserved.



Technically, the site was completely redeveloped. This was accompanied by an improvement in the database search function, which was now more intuitive to use than before. Another new feature was that, to make it clearer at first glance, the database now displayed covers in bold type and musical quotations in lean type.
For the first time, there was a web interface for the editorial staff with which the database could be edited, so that platform-dependent additional software was no longer necessary, but a browser was sufficient. Nowadays such a thing is almost taken for granted.
After 10 years of continuous work, we had collected more than 181,000 entries in April 2009. We suffered a bitter blow on April 23, 2010, when his girlfriend told us about Holger Kung's death. His work – the redevelopment of the website and database in 2007 and a list of artists that could be mixed up – lived on for many years. His entries, which he contributed to the database, will hopefully last forever.
Unfortunately, Holger did not leave any detailed documentation of his development work. It was therefore not practicable to continue his work. However, as the size of the database increased, the solution he developed came up against its limits. On September 14, 2010 we listed 200,000 entries, on November 5, 2012 already 250,000, on June 16, 2015 even 300,000, on July 15, 2017 impressive 350,000 entries. With workarounds, the system's limitations could still be pushed back for some time, so that it continued to run with hardly noticeable limitations for the user. Towards the end of 2017, however, it was no longer possible to maintain a reliably functioning search function. Increasingly, users were only able to see part of the data records matching their search.
Today's COVER.INFO
Fortunately, at that time our editor Falko Rickmeyer, who had meanwhile been trained as a software developer, was already in the process of completely redeveloping the website – together with Adrian Semmler, who helped to design the website, and Thomas Wagner, supported by the rest of the editorial staff, who contributed ideas for redesigning the data output. For the first time in the website's history, there was no longer a table view with cover versions on the left and originals on the right, but a chronological presentation that made it possible to display chains such as cover versions that have an original that samples another song which for his part quotes another song. For the first time, this new design also features a mobile view for usability on smartphones.On May 6, 2018, the redesigned website went online, and finally under the domain name we had dreamed of since 2001, but which had already been taken at an early stage: COVER.INFO. A domain other than coverinfo.de was necessary for the new concept anyway, because from now on the site was to be internationally oriented and therefore also made available completely in English (besides German), so that a regional domain extension would no longer fit.
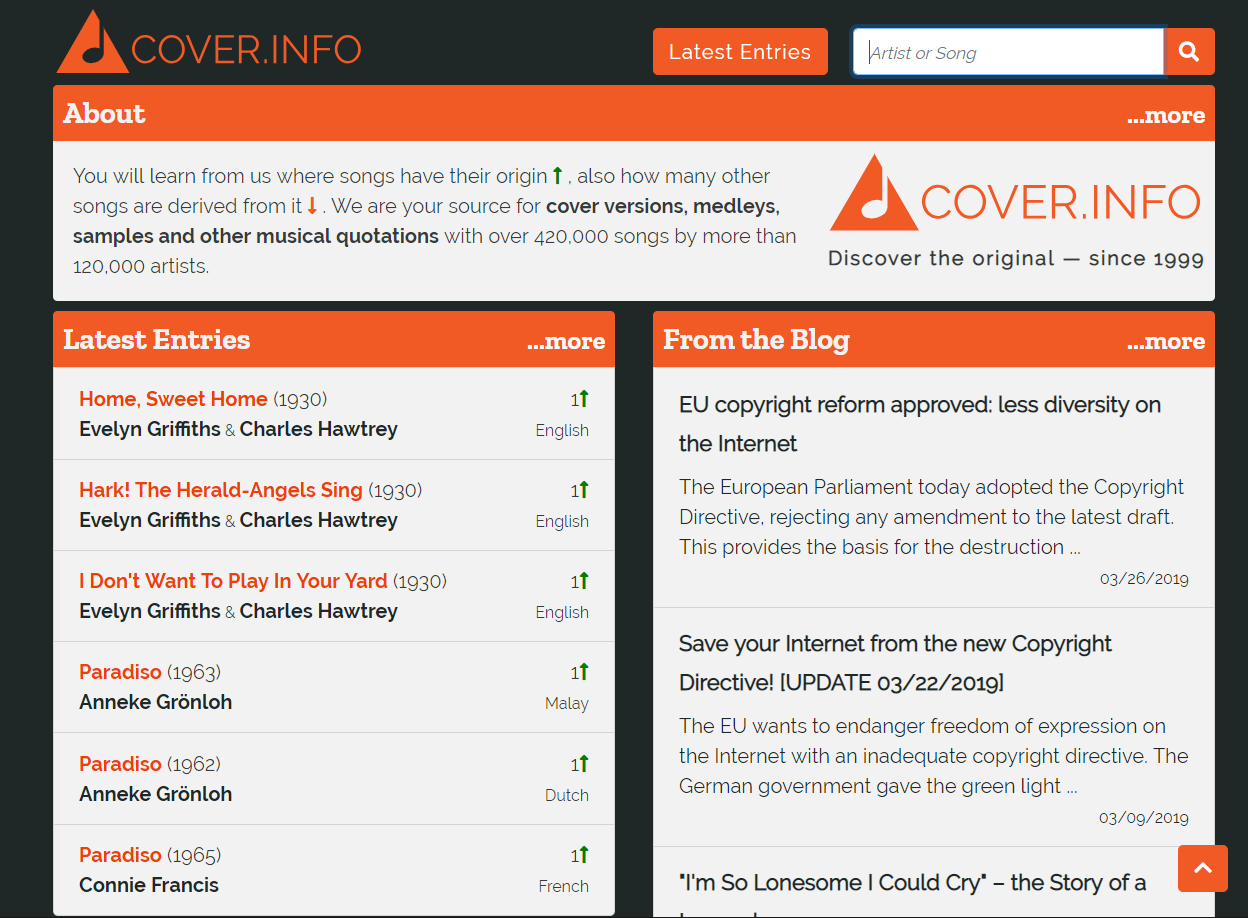

The new presentation has a disadvantage, which is why there were complaints from the users: It was no longer possible to see at a single glance which songs were covered by which artists or who covered their songs. You had to click each song individually to find out. We fixed this with the extended artist view that went live on July 19, 2018. It now offers on artist pages under the link "go to table view..." again a tabular representation of all songs of an artist – but now according to the new chronological concept the other way round than before with originals on the left and cover versions on the right.

COVER.INFO is still undergoing technical development in order to increase the range of functions and user-friendliness both for the public and for the editorial staff who maintains the data. Since June 1, 2018, the task of coordinating this has fallen to the non-profit association COVER.INFO n. e. V., who took over the responsibility for the maintenance of the website from Thomas Wagner. In this way, the dependence of the website on an individual is to be minimized to make it future-proof. In addition, tax-privileged donations for the maintenance of the website become possible.
The anniversary year at COVER.INFO
We have planned to present you more background information about us here in the blog in the next months.But now we're asking you! What from the history of 20 years of COVER.INFO do you still remember? Since when do you know us? Write it down in the comments under this article. The comment function is the replacement for the discussion forum which was closed on May 24, 2018.
